

Ziyi 'Zoe' Wang | 王子一
I am currently a research assistant at HCIL (UMD), supervised by Zijian Ding, and at FORTIS Lab (USC), supervised by Prof. Yue Zhao. I also have the pleasure of collaborating with Prof. Xiyang Hu, Prof. Xiang Yan, Prof. Yuan Li, and Prof. Fumeng Yang.
My research focus on using human-centered methods to design, develop, and evaluate interactive systems that empower people to effectively leverage, adapt, and extend AI in their work and daily lives, to enhance their capabilities and augment their cognition.
Hi! I’m Ziyi 👋, a Master’s student in Human-Computer Interaction @University of Maryland, College Park
I am actively seeking for 2026 Fall PhD position. Please don’t hesitate to contact me if my profile interests you!
News
Jan 2026 | We have a new paper “Persona-aware and Explainable Bikeability Assessment” on persona-conditioned vision–language models for explainable bikeability prediction. See our Preprint!
Jan 2026 | We have a new paper on multimodal ranking attacks against vision–language–model–based product search, showing how coordinated image–text perturbations can manipulate rankings. See our Preprint!
Nov 2025 | Our paper on mitigating hallucinations in LLMs using causal reasoning has been accepted to AAAI 2026! See our Preprint.
Oct 2025 | Our new paper “From Image Generation to Infrastructure Design” has been accepted to NeurIPS 2025 Workshop! It‘s a multi-agent pipeline for realistic street-design generation. See our Preprint!
Sep 2025 | We have a new paper introducing CareerPooler, a generative AI-powered pool-table metaphor system for career exploration that improves engagement, satisfaction, and clarity compared to chatbot baselines. See our Preprint!
Jul 2025 | Our new paper "Frontend Diffusion" has been accepted to IEEE VL/HCC 2025! It’s a multi-stage AI system that turns sketches into website code for junior researchers and designers. See our Preprint!
Jul 2025 | Our new paper "JailDAM" has been accepted to COLM 2025! It proposes an adaptive memory approach for jailbreak detection in vision-language models. See the Preprint!
Jun 2025 | We have a new paper accepted to ECML PKDD 2025 on leveraging LLMs for few-shot graph OOD detection. See our Preprint!
May 2025 | We have a new paper on zero-shot graph OOD detection using foundation models (GLIP-OOD). See our Preprint!
May 2025 | We have a new paper introducing GOE-LLM, a framework using LLMs to generate synthetic OOD nodes for graph OOD detection without requiring real OOD data. See our Preprint!
Please check my Google Scholar for my complete publication record.
Publications

CareerPooler: AI-Powered Metaphorical Pool Simulation Improves Experience and Outcomes in Career Exploration
Ziyi Wang, Ziwen Zeng, Yuan Li, Zijian Ding†
arXiv 2025
-
Career exploration is uncertain, requiring decisions with limited information and unpredictable outcomes. While generative AI offers new opportunities for career guidance, most systems rely on linear chat interfaces that produce overly comprehensive and idealized suggestions, overlooking the non-linear and effortful nature of real-world trajectories. We present CareerPooler, a generative AI-powered system that employs a pool-table metaphor to simulate career development as a spatial and narrative interaction. Users strike balls representing milestones, skills, and random events, where hints, collisions, and rebounds embody decision-making under uncertainty. In a within-subjects study with 24 participants, CareerPooler significantly improved engagement, satisfaction, and career clarity compared to a chatbot baseline. Qualitative findings show that spatial-narrative interaction fosters experience-based learning, resilience through setbacks, and reduced psychological burden. Our findings contribute to the design of AI-assisted career exploration systems and more broadly suggest that visually grounded analogical interactions can make generative systems engaging and satisfying.
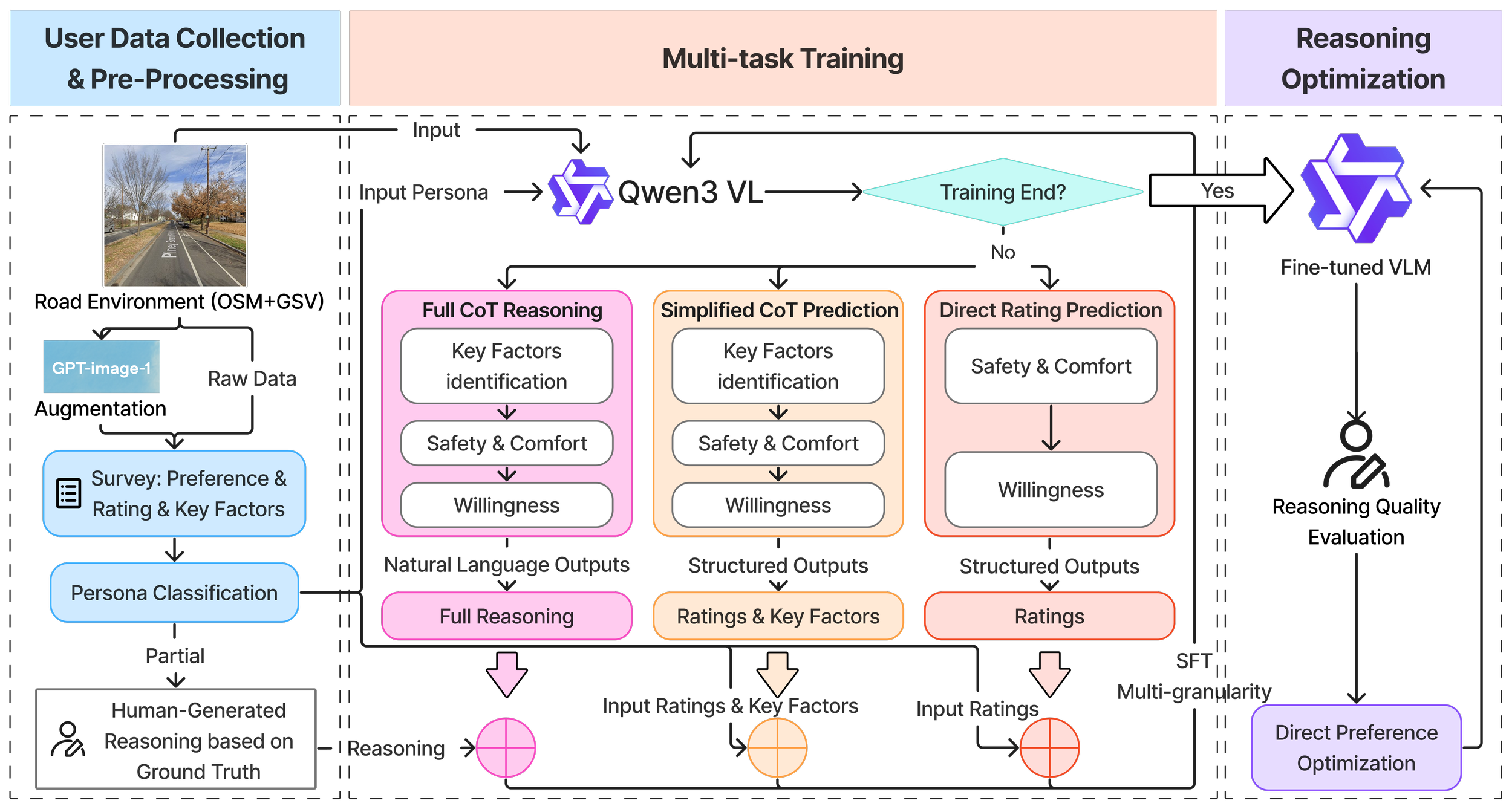
Persona-aware and Explainable Bikeability Assessment:
A Vision-Language Model Approach
Yilong Dai*, Ziyi Wang*, Chenguang Wang, Kexin Zhou, Yiheng Qian, Susu Xu, Xiang Yan
arXiv 2026
-
Bikeability assessment is essential for advancing sustainable urban transportation and creating cyclist-friendly cities, and it requires incorporating users' perceptions of safety and comfort. Yet existing perception-based bikeability assessment approaches face key limitations in capturing the complexity of road environments and adequately accounting for heterogeneity in subjective user perceptions. This paper proposes a persona-aware Vision-Language Model framework for bikeability assessment with three novel contributions: (i) theory-grounded persona conditioning based on established cyclist typology that generates persona-specific explanations via chain-of-thought reasoning; (ii) multi-granularity supervised fine-tuning that combines scarce expert-annotated reasoning with abundant user ratings for joint prediction and explainable assessment; and (iii) AI-enabled data augmentation that creates controlled paired data to isolate infrastructure variable impacts. To test and validate this framework, we developed a panoramic image-based crowdsourcing system and collected 12,400 persona-conditioned assessments from 427 cyclists. Experiment results show that the proposed framework offers competitive bikeability rating prediction while uniquely enabling explainable factor attribution.
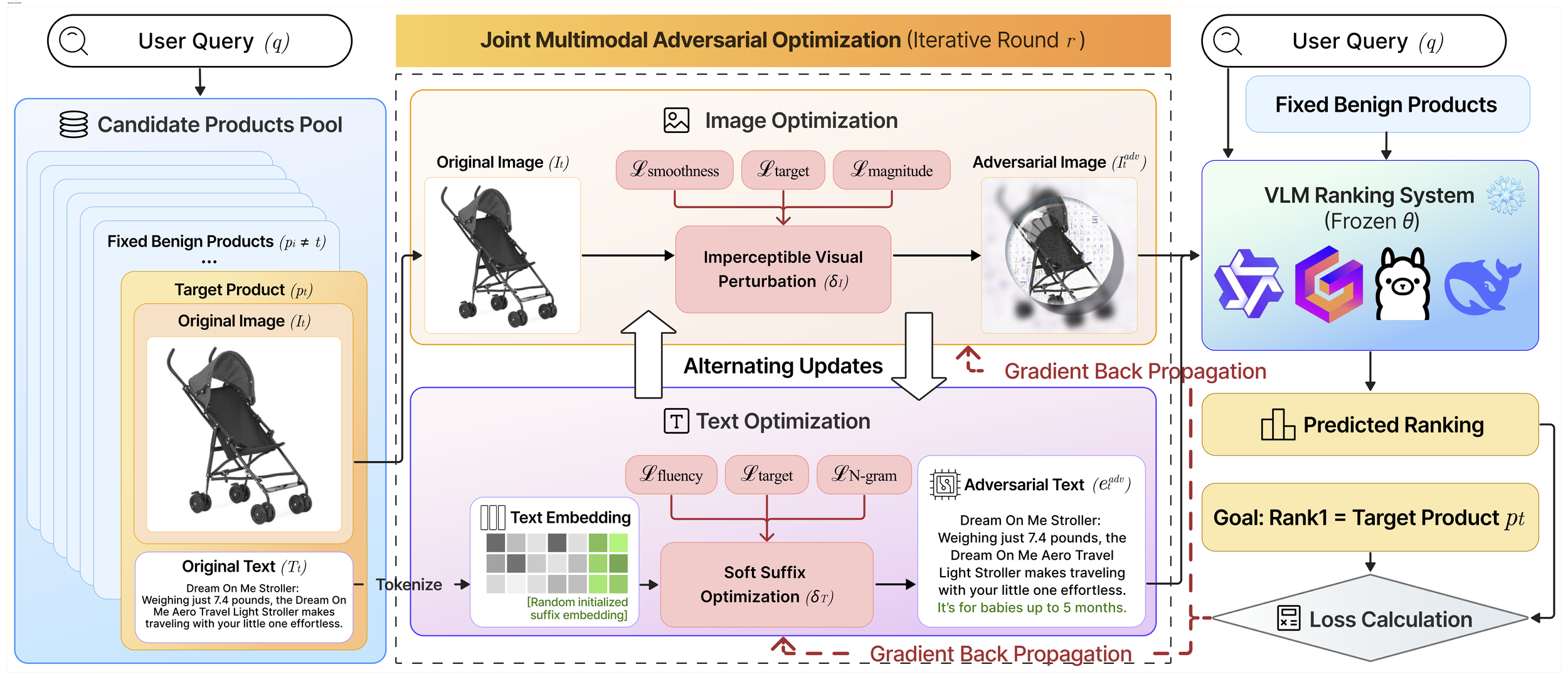
Multimodal Generative Engine Optimization: Rank Manipulation for Vision–Language Model Rankers
Yixuan Du, Chenxiao Yu, Haoyan Xu, Ziyi Wang, Yue Zhao, Xiyang Hu
SSRN 2025
-
Vision-Language Models (VLMs) are rapidly replacing unimodal encoders in modern retrieval and recommendation systems. While their capabilities are well-documented, their robustness against adversarial manipulation in competitive ranking scenarios remains largely unexplored. In this paper, we uncover a critical vulnerability in VLM-based product search: multimodal ranking attacks. We present a novel adversarial framework that enables a malicious actor to unfairly promote a target product by jointly optimizing imperceptible image perturbations and fluent textual suffixes. Unlike existing attacks that treat modalities in isolation, our method employs an alternating gradient-based optimization strategy to exploit the deep cross-modal coupling within the VLM. Extensive experiments on real-world datasets using state-of-the-art models demonstrate that our coordinated attack significantly outperforms text-only and image-only baselines. These findings reveal that multimodal synergy, typically a strength of VLMs, can be weaponized to compromise the integrity of search rankings without triggering conventional content filters.

Few-Shot Graph Out-of-Distribution Detection with LLMs
Haoyan Xu*, Zhengtao Yao*, Yushun Dong, Ziyi Wang, Ryan A. Rossi, Mengyuan Li, Yue Zhao†
ECML PKDD 2025
-
Existing methods for graph out-of-distribution (OOD) detection typically depend on training graph neural network (GNN) classifiers using a substantial amount of labeled in-distribution (ID) data. However, acquiring high-quality labeled nodes in text-attributed graphs (TAGs) is challenging and costly due to their complex textual and structural characteristics. Large language models (LLMs), known for their powerful zero-shot capabilities in textual tasks, show promise but struggle to naturally capture the critical structural information inherent to TAGs, limiting their direct effectiveness.
To address these challenges, we propose LLM-GOOD, a general framework that effectively combines the strengths of LLMs and GNNs to enhance data efficiency in graph OOD detection. Specifically, we first leverage LLMs' strong zero-shot capabilities to filter out likely OOD nodes, significantly reducing the human annotation burden. To minimize the usage and cost of the LLM, we employ it only to annotate a small subset of unlabeled nodes. We then train a lightweight GNN filter using these noisy labels, enabling efficient predictions of ID status for all other unlabeled nodes by leveraging both textual and structural information. After obtaining node embeddings from the GNN filter, we can apply informativeness-based methods to select the most valuable nodes for precise human annotation. Finally, we train the target ID classifier using these accurately annotated ID nodes. Extensive experiments on four real-world TAG datasets demonstrate that LLM-GOOD significantly reduces human annotation costs and outperforms state-of-the-art baselines in terms of both ID classification accuracy and OOD detection performance.

Frontend Diffusion: Empowering Self-Representation of Junior Researchers and Designers Through Agentic Workflows
Zijian Ding, Qinshi Zhang, Mohan Chi, Ziyi Wang
IEEE VL/HCC 2025
-
With the continuous development of generative AI's logical reasoning abilities, AI's growing code-generation potential poses challenges for both technical and creative professionals. But how can these advances be directed toward empowering junior researchers and designers who often require additional help to build and express their professional and personal identities? We present Frontend Diffusion, a multi-stage agentic system, transforms user-drawn layouts and textual prompts into refined website code, thereby supporting self-representation goals. A user study with 13 junior researchers and designers shows AI as a human capability enhancer rather than a replacement, and highlights the importance of bidirectional human-AI alignment. We then discuss future work such as leveraging AI for career development and fostering bidirectional human-AI alignment on the intent level.

Mitigating Hallucinations in Large Language Models via Causal Reasoning
Yuangang Li*, Yiqing Shen*, Yi Nian, Jiechao Gao, Ziyi Wang, Chenxiao Yu, Shawn Li, Jie Wang, Xiyang Hu, Yue Zhao†
AAAI 2026
-
Large language models (LLMs) exhibit logically inconsistent hallucinations that appear coherent yet violate reasoning principles, with recent research suggesting an inverse relationship between causal reasoning capabilities and such hallucinations. However, existing reasoning approaches in LLMs, such as Chain-of-Thought (CoT) and its graph-based variants, operate at the linguistic token level rather than modeling the underlying causal relationships between variables, lacking the ability to represent conditional independencies or satisfy causal identification assumptions. To bridge this gap, we introduce causal-DAG construction and reasoning (CDCR-SFT), a supervised fine-tuning framework that trains LLMs to explicitly construct variable-level directed acyclic graph (DAG) and then perform reasoning over it. Moreover, we present a dataset comprising 25,368 samples (CausalDR), where each sample includes an input question, explicit causal DAG, graph-based reasoning trace, and validated answer. Experiments on four LLMs across eight tasks show that CDCR-SFT improves the causal reasoning capability with the state-of-the-art 95.33% accuracy on CLADDER (surpassing human performance of 94.8% for the first time) and reduces the hallucination on HaluEval with 10% improvements. It demonstrates that explicit causal structure modeling in LLMs can effectively mitigate logical inconsistencies in LLM outputs.

JailDAM: Jailbreak Detection with Adaptive Memory for Vision-Language Model
Yi Nian*, Shenzhe Zhu*, Yuehan Qin, Li Li, Ziyi Wang, Chaowei Xiao, Yue Zhao†
COLM 2025
-
Multimodal large language models (MLLMs) excel in vision-language tasks but also pose significant risks of generating harmful content, particularly through jailbreak attacks. Jailbreak attacks refer to intentional manipulations that bypass safety mechanisms in models, leading to the generation of inappropriate or unsafe content. Detecting such attacks is critical to ensuring the responsible deployment of MLLMs. Existing jailbreak detection methods face three primary challenges: (1) Many rely on model hidden states or gradients, limiting their applicability to white-box models, where the internal workings of the model are accessible; (2) They involve high computational overhead from uncertainty-based analysis, which limits real-time detection, and (3) They require fully labeled harmful datasets, which are often scarce in real-world settings. To address these issues, we introduce a test-time adaptive framework called JAILDAM. Our method leverages a memory-based approach guided by policy-driven unsafe knowledge representations, eliminating the need for explicit exposure to harmful data. By dynamically updating unsafe knowledge during test-time, our framework improves generalization to unseen jailbreak strategies while maintaining efficiency. Experiments on multiple VLM jailbreak benchmarks demonstrate that JAILDAM delivers state-of-the-art performance in harmful content detection, improving both accuracy and speed.

From Image Generation to Infrastructure Design: a Multi-agent Pipeline for Street Design Generation
Chenguang Wang, Xiang Yan, Yilong Dai, Ziyi Wang, Susu Xu†
NeurIPS 2025 Workshop
-
Realistic visual renderings of street-design scenarios are essential for public engagement in active transportation planning. Traditional approaches are labor-intensive, hindering collective deliberation and collaborative decision-making. While AI-assisted generative design shows transformative potential by enabling rapid creation of design scenarios, existing generative approaches typically require large amounts of domain-specific training data and struggle to enable precise spatial variations of design/configuration in complex street-view scenes. We introduce a multi-agent system that edits and redesigns bicycle facilities directly on real-world street-view imagery. The framework integrates lane localization, prompt optimization, design generation, and automated evaluation to synthesize realistic, contextually appropriate designs. Experiments across diverse urban scenarios demonstrate that the system can adapt to varying road geometries and environmental conditions, consistently yielding visually coherent and instruction-compliant results. This work establishes a foundation for applying multi-agent pipelines to transportation infrastructure planning and facility design.

Graph Synthetic Out-of-Distribution Exposure with Large Language Models
Haoyan Xu*, Zhengtao Yao*, Ziyi Wang, Zhan Cheng, Xiyang Hu, Mengyuan Li, Yue Zhao†
arXiv 2025
-
Out-of-distribution (OOD) detection in graphs is critical for ensuring model robustness in open-world and safety-sensitive applications. Existing approaches to graph OOD detection typically involve training an in-distribution (ID) classifier using only ID data, followed by the application of post-hoc OOD scoring techniques. Although OOD exposure - introducing auxiliary OOD samples during training - has proven to be an effective strategy for enhancing detection performance, current methods in the graph domain generally assume access to a set of real OOD nodes. This assumption, however, is often impractical due to the difficulty and cost of acquiring representative OOD samples. In this paper, we introduce GOE-LLM, a novel framework that leverages Large Language Models (LLMs) for OOD exposure in graph OOD detection without requiring real OOD nodes. GOE-LLM introduces two pipelines: (1) identifying pseudo-OOD nodes from the initially unlabeled graph using zero-shot LLM annotations, and (2) generating semantically informative synthetic OOD nodes via LLM-prompted text generation. These pseudo-OOD nodes are then used to regularize the training of the ID classifier for improved OOD awareness. We evaluate our approach across multiple benchmark datasets, showing that GOE-LLM significantly outperforms state-of-the-art graph OOD detection methods that do not use OOD exposure and achieves comparable performance to those relying on real OOD data.

GLIP-OOD: Zero-Shot Graph OOD Detection with Foundation Model
Haoyan Xu*, Zhengtao Yao*, Xuzhi Zhang, Ziyi Wang, Langzhou He, Yushun Dong, Philip S. Yu, Mengyuan Li, Yue Zhao†
arXiv 2025
-
Out-of-distribution (OOD) detection is critical for ensuring the safety and reliability of machine learning systems, particularly in dynamic and open-world environments. In the vision and text domains, zero-shot OOD detection - which requires no training on in-distribution (ID) data - has made significant progress through the use of large-scale pretrained models such as vision-language models (VLMs) and large language models (LLMs). However, zero-shot OOD detection in graph-structured data remains largely unexplored, primarily due to the challenges posed by complex relational structures and the absence of powerful, large-scale pretrained models for graphs. In this work, we take the first step toward enabling zero-shot graph OOD detection by leveraging a graph foundation model (GFM). We show that, when provided only with class label names, the GFM can perform OOD detection without any node-level supervision - outperforming existing supervised methods across multiple datasets. To address the more practical setting where OOD label names are unavailable, we introduce GLIP-OOD, a novel framework that employs LLMs to generate semantically informative pseudo-OOD labels from unlabeled data. These labels enable the GFM to capture nuanced semantic boundaries between ID and OOD classes and perform fine-grained OOD detection - without requiring any labeled nodes. Our approach is the first to enable node-level graph OOD detection in a fully zero-shot setting, and achieves state-of-the-art performance on four benchmark text-attributed graph datasets.
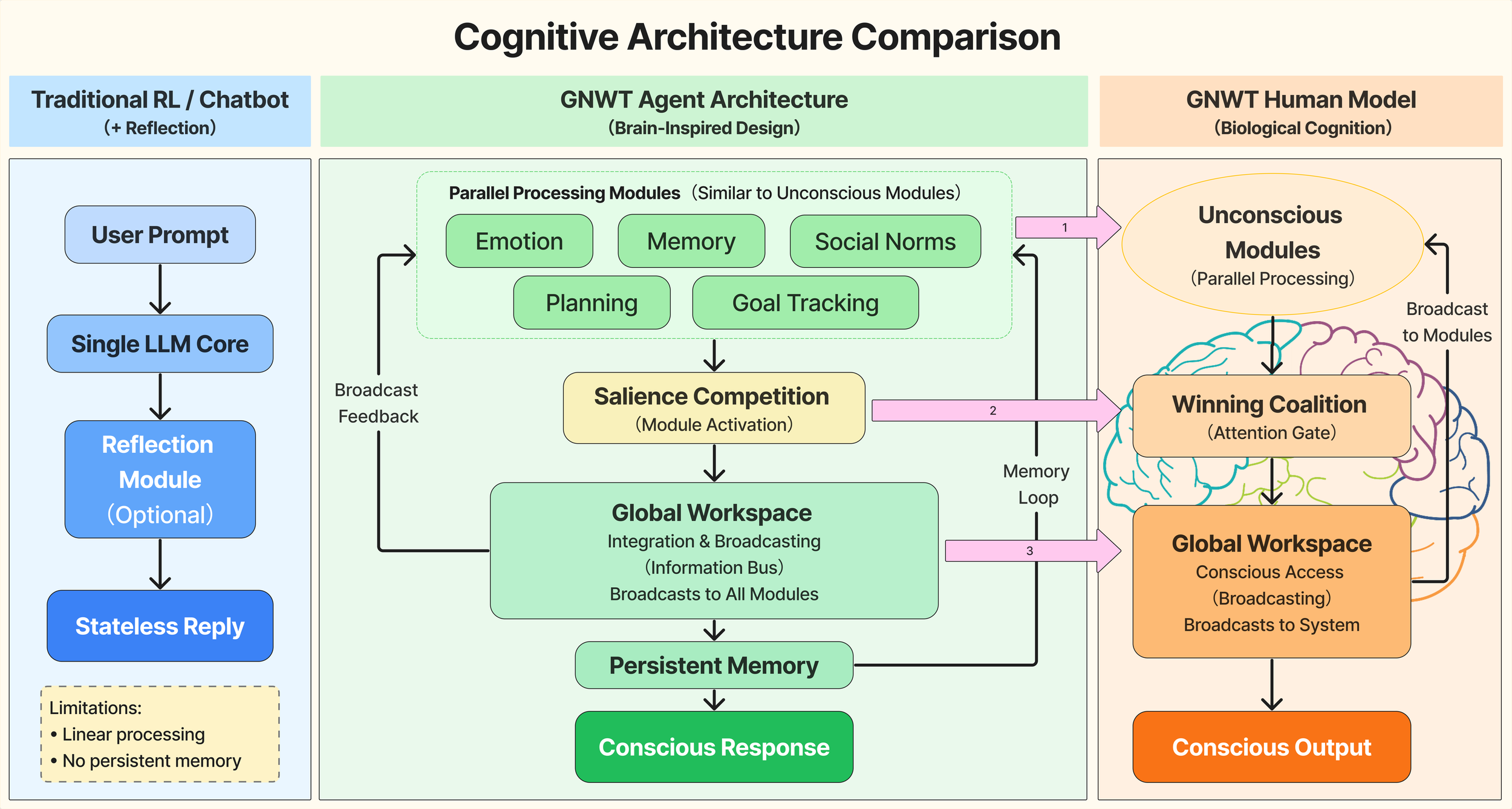
CogniPair: From LLM Chatbots to Conscious AI Agents -- GNWT-Based Multi-Agent Digital Twins for Social Pairing -- Dating & Hiring Applications
Wanghao Ye, Sihan Chen, Yiting Wang, Shwai He, Bowei Tian, Guoheng Sun, Ziyi Wang, et.al.
arXiv 2025
-
Current large language model (LLM) agents lack authentic human psychological processes necessary for genuine digital twins and social AI applications. To address this limitation, we present a computational implementation of Global Workspace Theory (GNWT) that integrates human cognitive architecture principles into LLM agents, creating specialized sub-agents for emotion, memory, social norms, planning, and goal-tracking coordinated through a global workspace mechanism. However, authentic digital twins require accurate personality initialization. We therefore develop a novel adventure-based personality test that evaluates true personality through behavioral choices within interactive scenarios, bypassing self-presentation bias found in traditional assessments. Building on these innovations, our CogniPair platform enables digital twins to engage in realistic simulated dating interactions and job interviews before real encounters, providing bidirectional cultural fit assessment for both romantic compatibility and workplace matching. Validation using 551 GNWT-Agents and Columbia University Speed Dating dataset demonstrates 72% correlation with human attraction patterns, 77.8% match prediction accuracy, and 74% agreement in human validation studies. This work advances psychological authenticity in LLM agents and establishes a foundation for intelligent dating platforms and HR technology solutions.